DistributedDataParallel non-floating point dtype parameter with
$ 17.50 · 4.6 (569) · In stock
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re

4. Memory and Compute Optimizations - Generative AI on AWS [Book]
apex/apex/parallel/distributed.py at master · NVIDIA/apex · GitHub

Non-uniform Distribution of Floating-Point Numbers
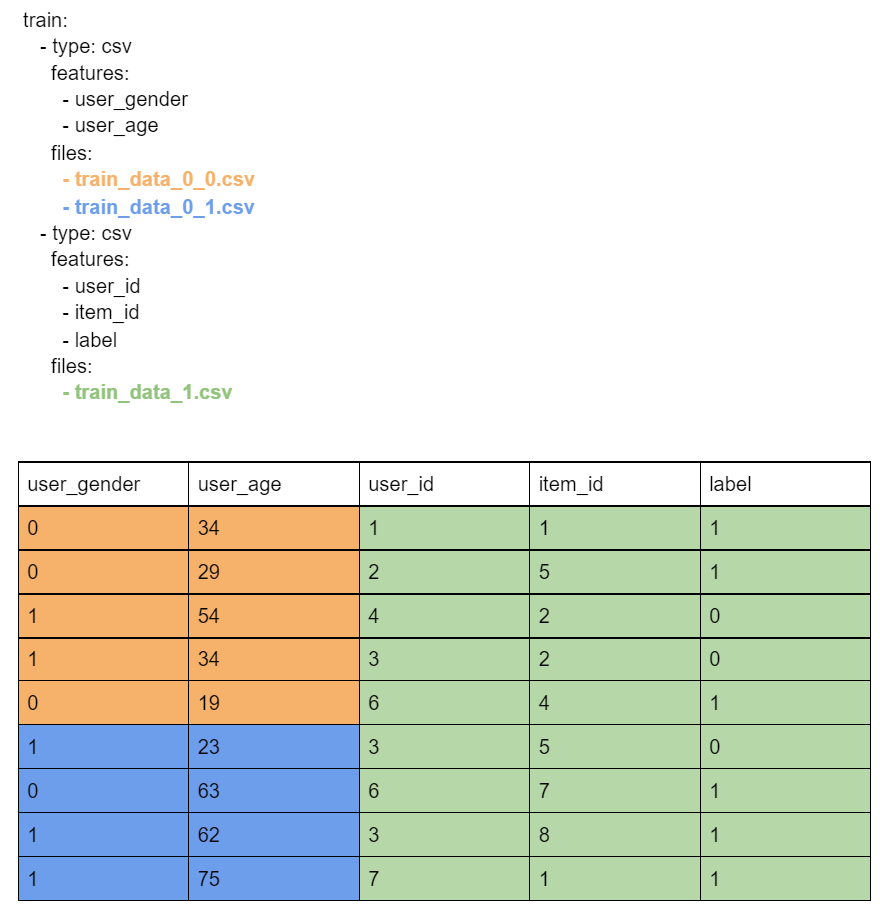
NCF for PyTorch

How to train on multiple GPUs the Informer model for time series forecasting? - Accelerate - Hugging Face Forums

distributed data parallel, gloo backend works, but nccl deadlock · Issue #17745 · pytorch/pytorch · GitHub

Distributed PyTorch Modelling, Model Optimization, and Deployment

Does moxing.tensorflow Contain the Entire TensorFlow? How Do I Perform Local Fine Tune on the Generated Checkpoint?_ModelArts_Troubleshooting_MoXing
A comprehensive guide of Distributed Data Parallel (DDP), by François Porcher
Multi-Process Single-GPU DistributedDataParallel bug · Issue #1218 · espnet/espnet · GitHub
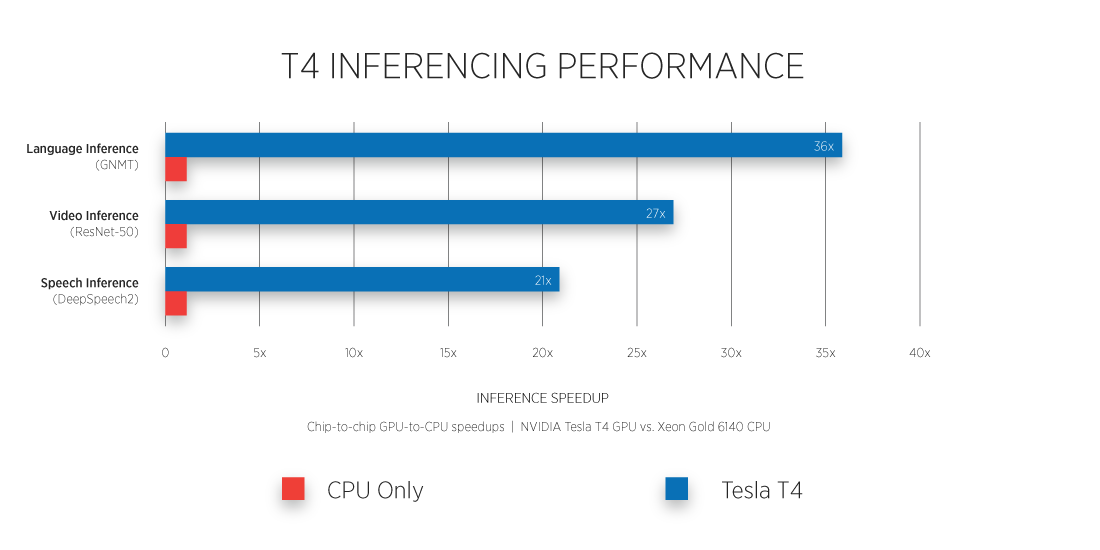
PyTorch Release v1.2.0