Reinforcement Learning as a fine-tuning paradigm
$ 19.99 · 4.9 (231) · In stock

Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.
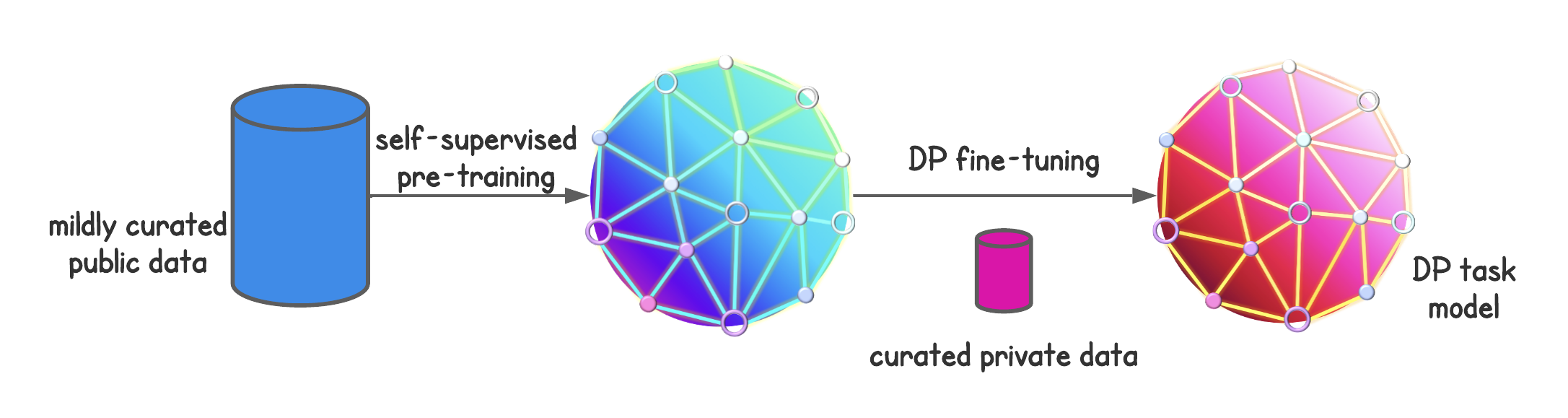
Differential Privacy - Differentially private deep learning can be

Reinforcement Learning Pretraining for Reinforcement Learning
The AiEdge+: How to fine-tune Large Language Models with Intermediary models

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds
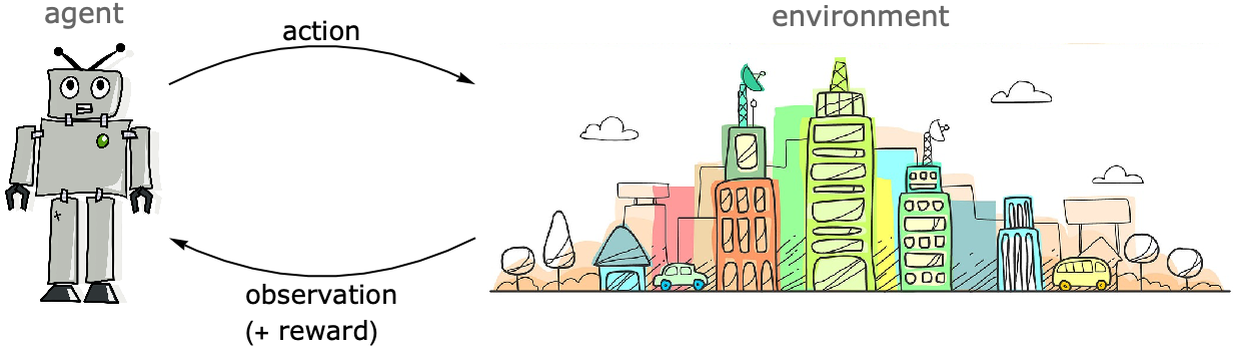
Machine Learning Paradigms - Introduction to Machine Learning

Emergent Mind on X: Reflexion revolutionizes LLMs by using verbal
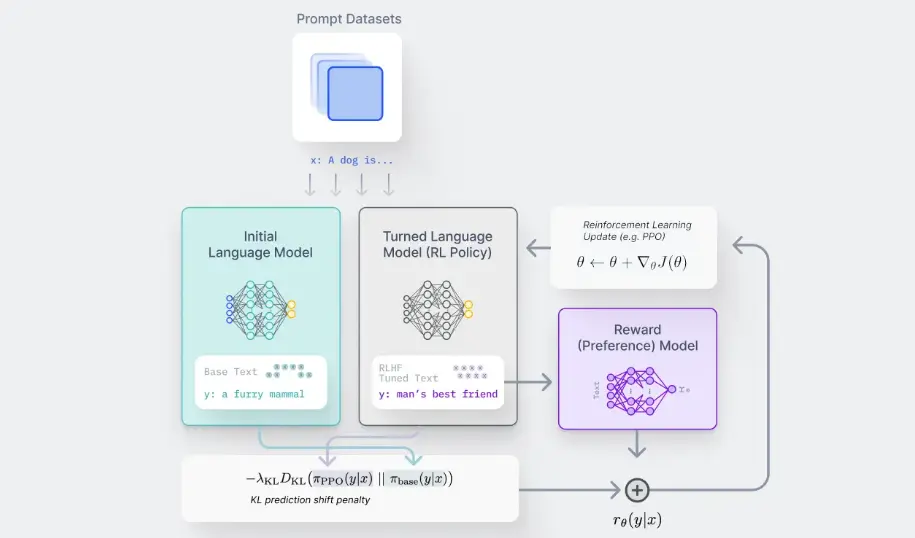
Complete Guide On Fine-Tuning LLMs using RLHF
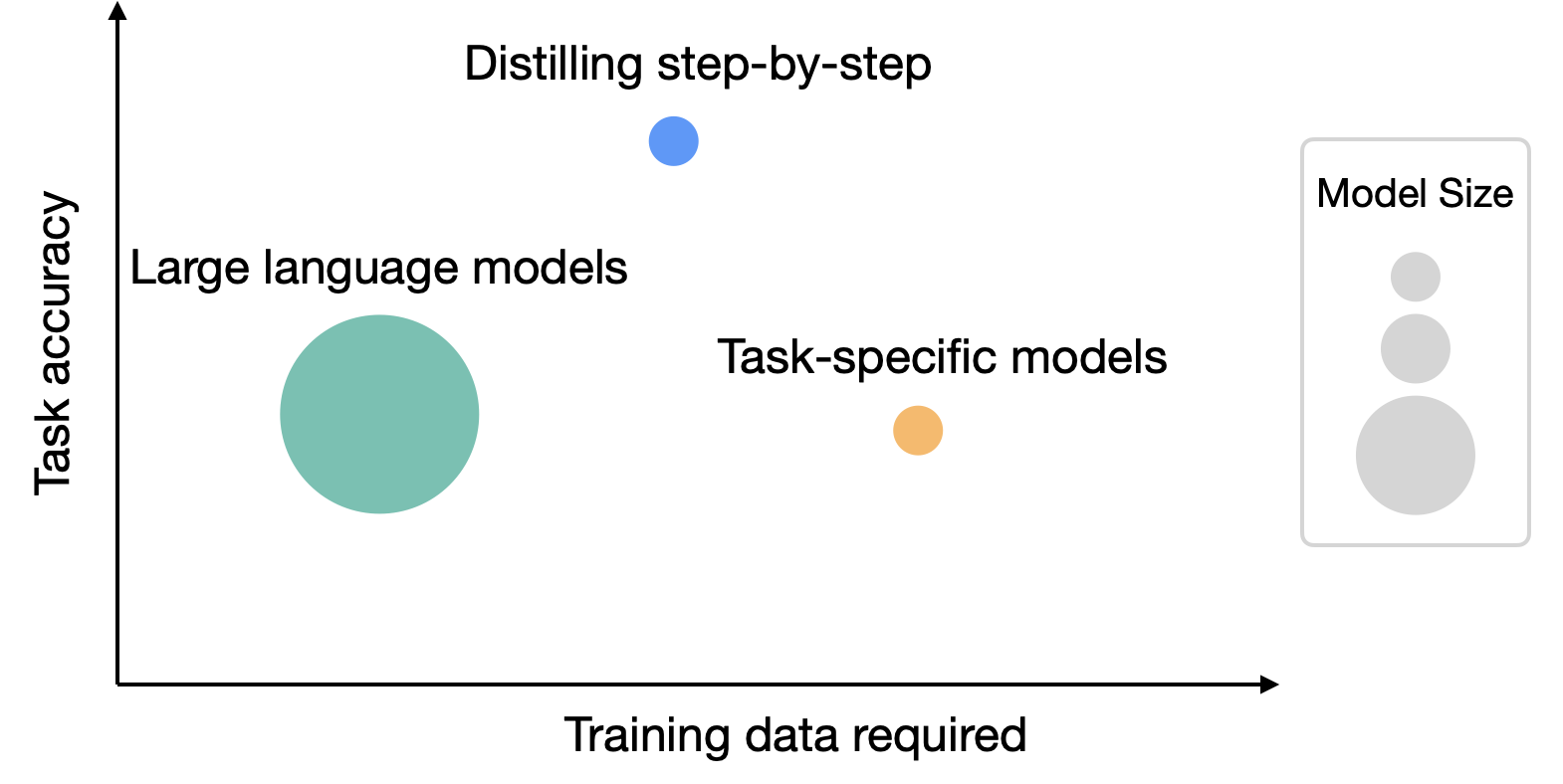
Distilling step-by-step: Outperforming larger language models with

arxiv-sanity

LoRA — Intuitively and Exhaustively Explained

The uneasy relationship between deep learning and (classical

5: GPT-3 Gets Better with RL, Hugging Face & Stable-baselines3, Meet Evolution Gym, Offline RL's Tailwinds, by Enes Bilgin, RL Agent
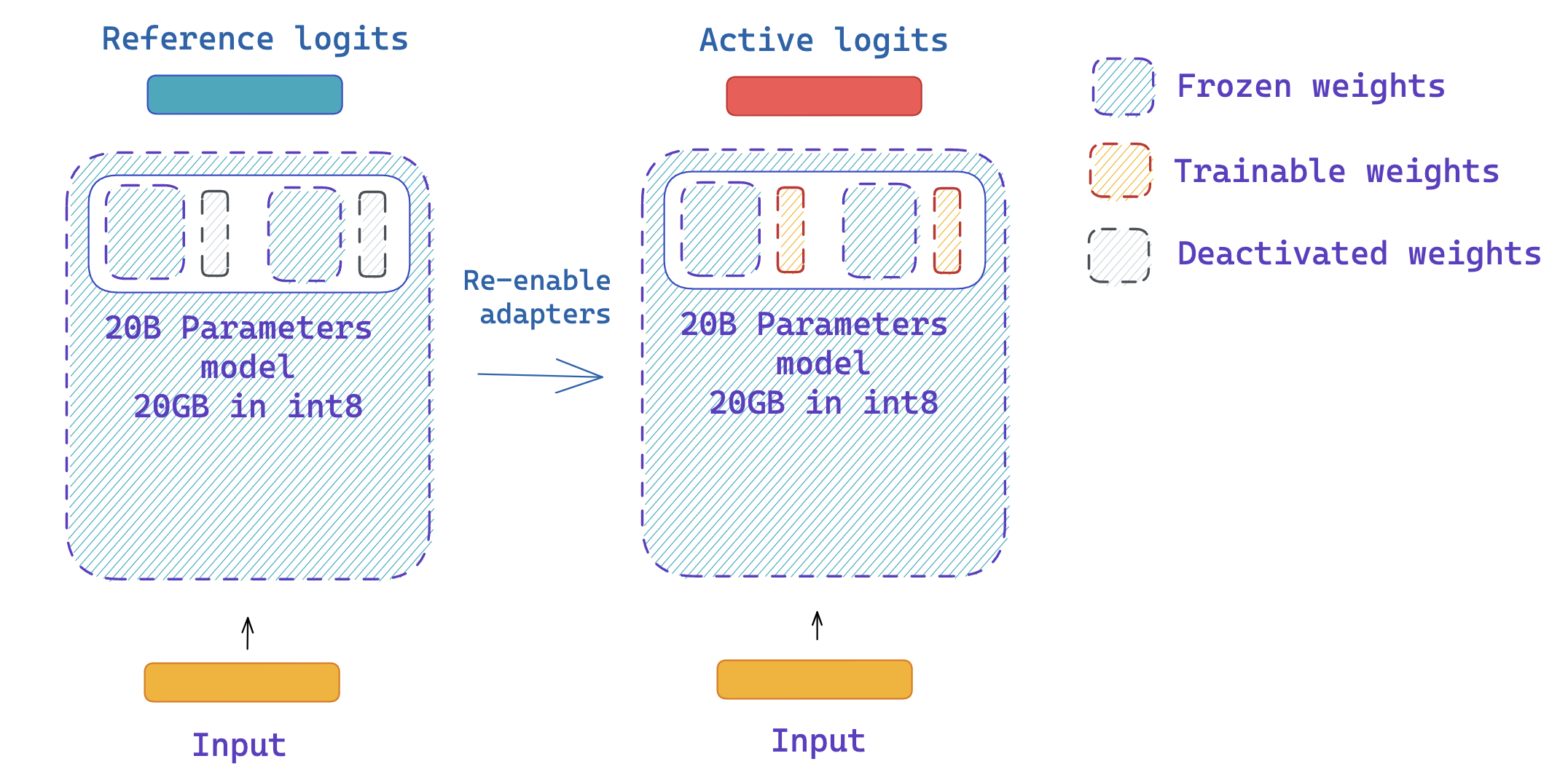
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

9 Reinforcement Learning Real-Life Applications
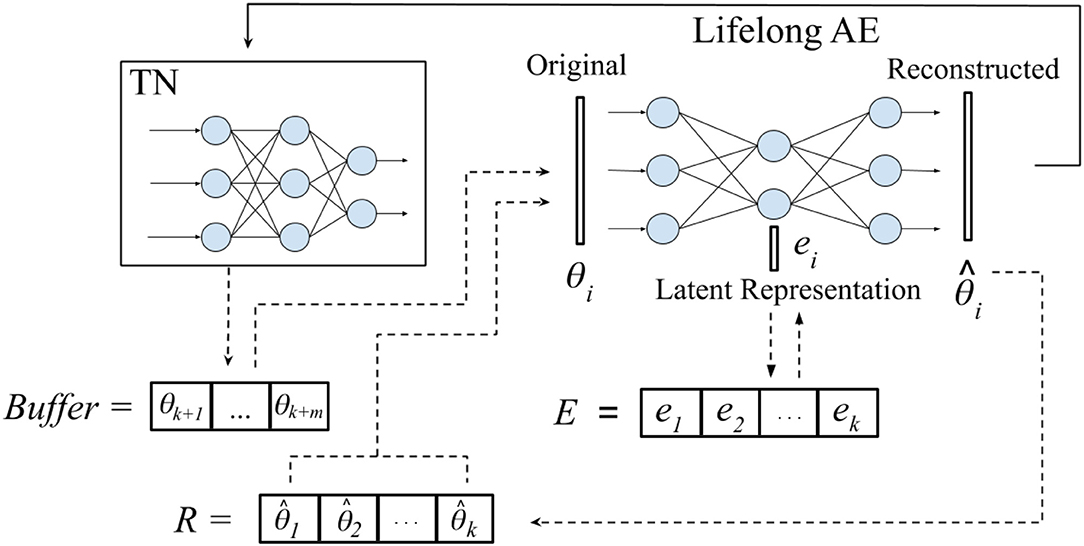
Frontiers Self-Net: Lifelong Learning via Continual Self-Modeling